
Thoughts on OpenAI's o3
and where I'd apply expensive but effective CoT models today

Hello World! I’ve long told myself that I should start writing more publicly and what better time to do so than to talk briefly about the latest OpenAI model, o3.
The ARC-AGI benchmark
Francois Collet, the creator of Keras, argued in 2019 that task-specific benchmarks are doomed to overfit in some shape or form. Overfitting can arise explicitly from sufficient data coverage in a domain or implicitly from biases in the training or evaluation sets, feature over-reliance, or other algorithmic artifacts. To combat this, he released a benchmark called the Abstract Reasoning Corpus (ARC) in his paper On the Measure of Intelligence. This benchmark is designed to evaluate the general reasoning abilities of AI systems beyond narrow tasks. It consists of abstract pattern-recognition problems that require understanding, generalization, and creativity to solve.
The benchmark emphasizes reasoning over statistical pattern-matching, measuring how well AI systems can approach tasks they haven't been explicitly trained on.
The following excerpt and figure describes the dataset well: “ARC-AGI consists of unique training and evaluation tasks. Each task contains input-output examples. The puzzle-like inputs and outputs present a grid where each square can be one of ten colors. A grid can be any height or width between 1x1 and 30x30”

While I don’t consider ARC-AGI to be the ultimate benchmark for AGI, I have long believed that it remains an exceptionally robust measure of a model’s general reasoning versatility that clearly gets around memorization and demonstrates the ability to solve novel, unstructured problems.
The community has experimented with a number of approaches to attacking the ARC-AGI benchmark, including both deep learning and “classical” statistical learning approaches. Not surprisingly most of the recent ones were LLM based. The ARC team published a technical paper talking about some of the best 2024 approaches. We’ll cover some of these approaches in another post, but the best results before o3 hovered around ~55% (on the private held-out set), achieved in the work titled Combining Induction and Transduction for Abstract Reasoning by Li, et. al. Human performance is reported to be around 85%.
o3 results
o3 scored an amazing 75.7% on ARC-AGI’s semi-private eval set in the low compute mode and 87.5% in the high compute mode. There are a few disclaimers here. o3 was reportedly fine-tuned on 300 of 400 ARC training tasks and the runs were on the semi-private eval set (presumably because of the inability to run o3 in complete isolation [no internet]). Nevertheless, it still outperforms in other well known benchmarks:
SWE bench - simulates real-world software engineering issues by providing a codebase and an issue description. o3 scored 71.7%, up from 62.2% by the Aide team, and 49% by Claude 3.5 (sonnet).
Codeforces - competitive programming problems (similar to those in the Informatics Olympiad [IOI]) . o3 scores an Elo of 2727, up from 1891 rating for o1.
AIME 2024 - math problems - o3 made just one error (whopping my personal best of three errors in high school!).
GPQA - multiple choice in bio, physics and chemistry. o3 scores 87.7% up from 78% from o1 and Claude.
EpochAI’s FrontierMath - hard math problems. o3 scored 25.2% up from 2%
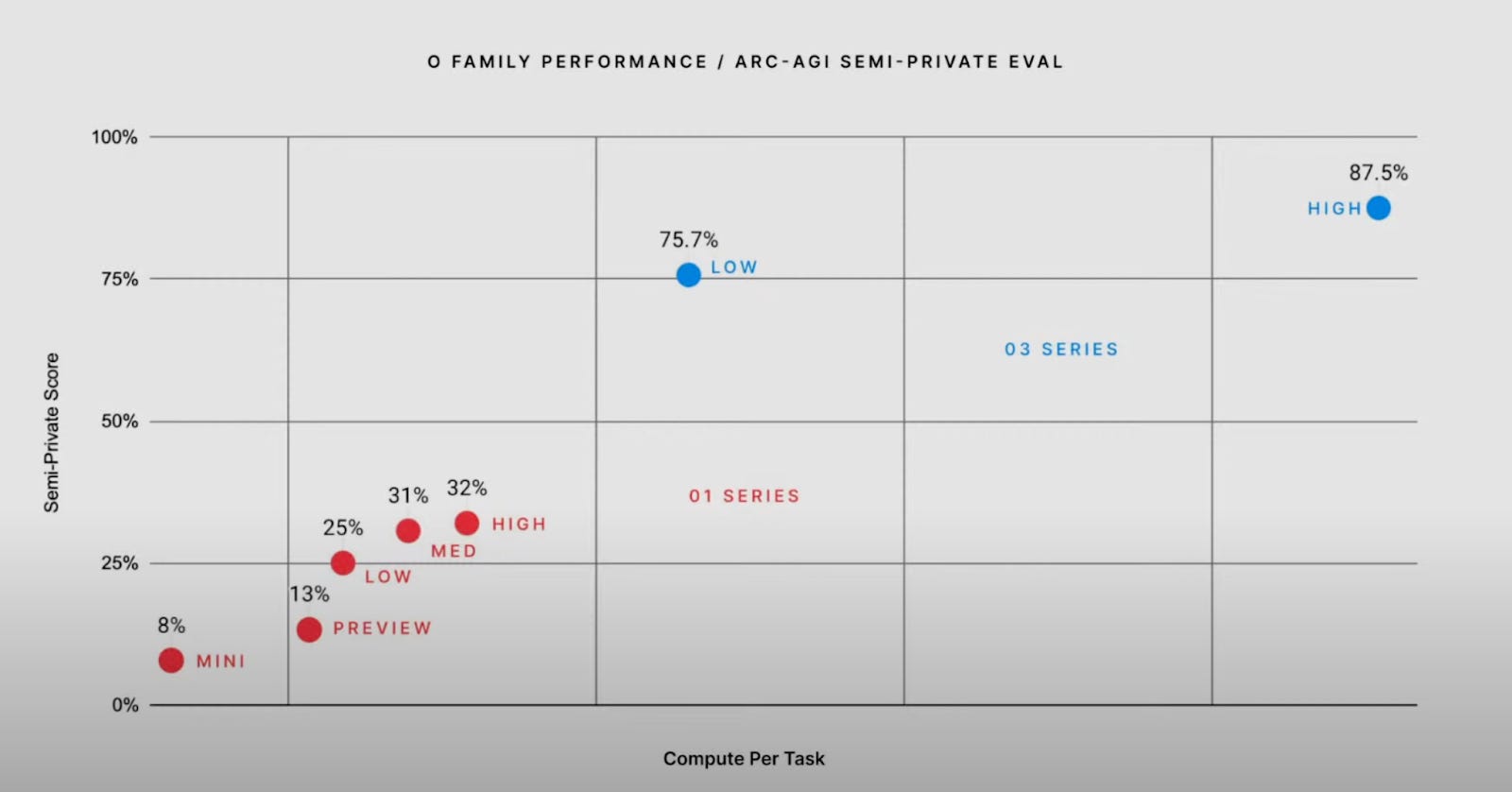
These are very impressive results across the board and we have a lot to be excited about. Given what we’ve seen with o1 and now o3, it seems that Chain of Thought (CoT) models drive the best performance for complex multi-step tasks given an unlimited inference cost and latency budget. Even Anthropic’s Claude, which to our knowledge was not trained directly to decompose problems, still encourages the use of CoT via prompting.
CoT models for startups today
At OpenPay and in my role as a Venture Partner for Bessemer Venture Partners, I think a lot about how the latest models and frameworks affect startups. The very nature of CoT involves taking a complex query and breaking it down into step-by-step reasoning. The obvious trade-off here is the move towards inference-time-compute (as opposed to training) to achieve performance. Even in the “low compute” setting, running inference on o3 allegedly costs a whopping ~$20 per query. Models will only get cheaper and faster in time, but until then what might this mean for some AI use cases today:
Agentic frameworks and architectures - these high cost CoT models are clearly not usable for most sub-task/tool calling components of agentic architectures today, especially because for most subtasks smaller models will do just fine. However, high value tasks that are less frequently called or called at the top of the stack such as planning or meta prompting are prime candidates for these high performance, high cost models.
Code Generation and Dev tooling - the cost of running o3 is prohibitive for quick and iterative conversation right now, but there are many use cases where escalating to what should be closer to an L7 engineer clears the threshold of value. I think there can be good product experiences designed around this, especially human-in-the-loop experiences that know how to clarify and re-plan.
High Value Vertical SaaS - We all know models will keep getting better at generalizing and reasoning over time, unlocking more and more use cases. But high value use cases that are relatively asynchronous, tolerant to error and where elegant product experiences can be built could be early beneficiaries. Fields like legal, research and consulting all clear the bar.
Data labeling and Post training - more fields can benefit from training vertical CoT models, which in turn will require human annotated “chains-of-thought” labels (step-by-step reasoning labels, intermediate annotations, etc) for post-training. Companies can probably be built around the next generation of labeling tools to properly support these complex labeling tasks. This might be extended further to provide the end-to-end post-training loop.
Synthetic data - a good friend and mentor Alex Kvamme thinks there is a lot to be built here, and I agree. Synthetic data both in terms of training CoT models and distilling CoT models into simpler task specific models.
What a time to be alive! 2025 will be a big year for AI and the builders around it. Thanks for reading.